行列の乗算の高速化¶
GPUには多数の計算ユニットがあり計算は高速なのですがメモリの通り道(メモリバス)は1つしかないので、多数の計算ユニットが一斉にメモリ内のあちこちを参照するとたちまち渋滞がおきてしまいます。
GPGPUで高速に数値計算をするときに最も重要なのはできるだけ連続したメモリ領域をアクセスすることです。
このことを念頭に置いてテクスチャBの配置を以下のように変えてみます。
数学的にはBは行と列が入れ替わった転置行列になっています。
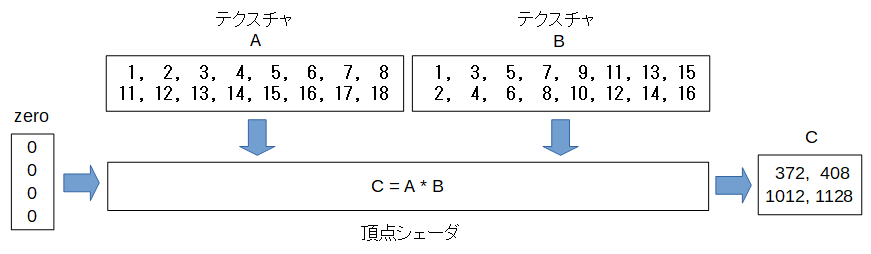
こうすると例えばCの1行1列の値は以下のようになり、メモリ内の連続した領域をアクセスするようになりました。
Aの1行目とBの1行目の内積 = 1 * 1 + 2 * 3 + 3 * 5 + 4 * 7 + 5 * 9 + 6 * 11 + 7 * 13 + 8 * 15
さらにテクスチャの値は vec4 として4次元のベクトルとしてアクセスでき、4次元のベクトルの内積が使えることを利用するとさらに高速化できます。
Bは転置したのでBの行数を使って、rowとcolを計算します。
int row = gl_VertexID / B_sz.y;
int col = gl_VertexID % B_sz.y;
Bは転置したので texelFetch の引数の行と列を入れ替えます。
// Bのcol行i列の値を取得します。
vec4 b = texelFetch(B, ivec2(i, col), 0);
テクスチャから**vec4**の単位で値を取得したので、
sum += dot(a, b);